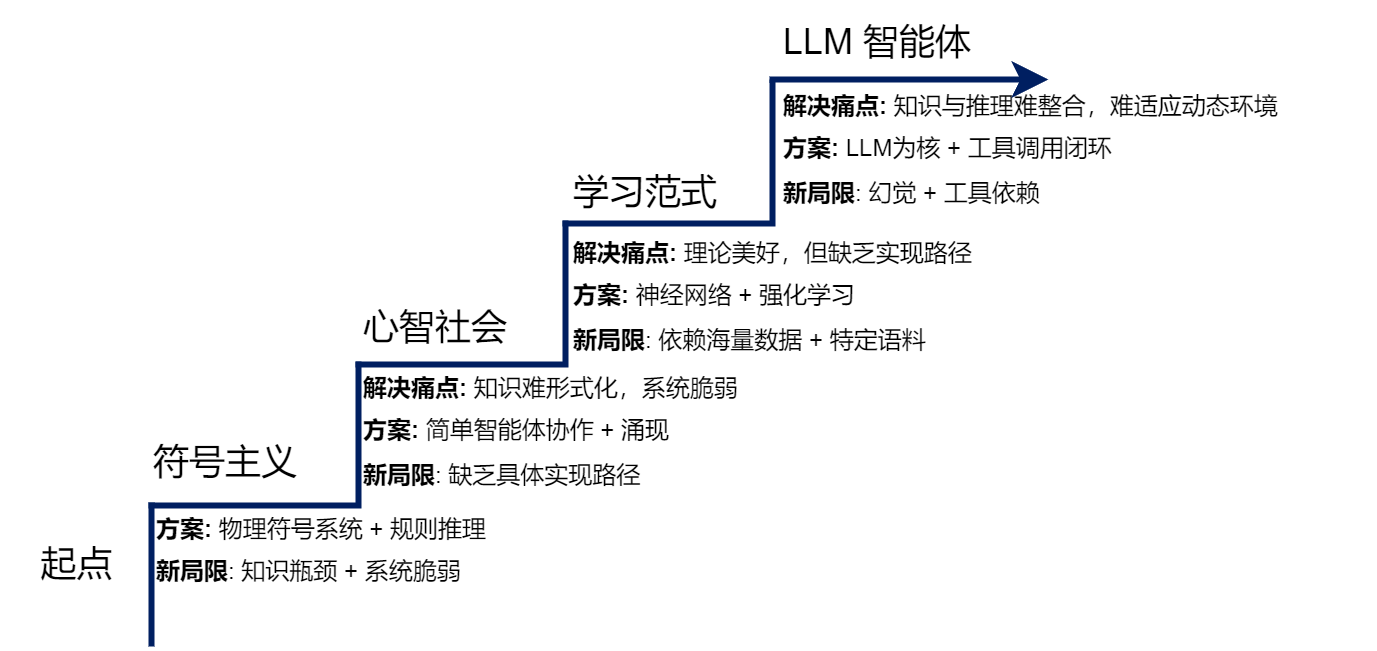
图 2.1 AI智能体的演进阶梯
图 2.1 AI智能体的演进阶梯

图 2.2 物理符号系统的构成元素

图 2.3 专家系统的通用架构

图 2.4 MYCIN反向链推理流程示意图

图 2.5 SHRDLU的“积木世界”交互界面

图 2.6 “心智社会”中搭建积木塔行为的涌现机制示意图

图 2.7 符号主义与联结主义范式对比

图 2.8 强化学习的核心交互循环

图 2.9 “预训练-微调”范式示意图

图 2.10 LLM驱动的智能体核心组件架构

图 2.11 智能体发展演进时间线(未完全版)

图 2.12 AI Agent 技术栈概览